Kubernetes Updates
Hoe gaan de patches van Kubernetes, precies in zijn werk? Lees het op deze pagina. Wij ondersteunen standaard alleen Kubernetes versies die onder support zijn. Kijk hier welke releases dit zijn.
Het updaten van Kubernetes
Wat we doen
Het updaten van clusters doen we binnen het afgesproken onderhoudsvenster. Voor we updates uitvoeren zullen we je hiervan op de hoogte stellen. Zo krijg je tijd om een backup te maken of wanneer het niet uitkomt de update uit te stellen. Wij updaten alleen Kubernetes en zijn componenten, de wijzigingen kun je hier terug vinden.
Update Overwegingen
Indien je tools en applicaties werken volgens de cloud-native methoden, zal het cluster geupgrade worden zonder downtime. Om jouw diensten ook zonder downtime te laten functioneren tijdens de upgrade, zijn hier enkele hints.

Implementeer Graceful Shutdowns
Het is belangrijk dat diensten zich kunnen herstellen na een geforceerde stop. Bekijk de pagina Termination of Pods uit de Kubernetes documentatie hoe een Pod Lifecycle specifiek werkt, mogelijk zit hier wat maatwerk aan middels een PreStop hook voor jouw pod.
Tijdens een upgrade van je Kubernetes cluster worden de volgende stappen ondernomen om pods af te sluiten:
- Pods worden op status
Terminatinggezet. - Indien geconfigureerd wordt de
preStophook uitgevoerd. - A SIGTERM signaal wordt gegeven aan de Pod, hierdoor weet de Pod dat deze wordt afgesloten.
- Kubernetes wacht op de grace period, standaard 30 seconden.
- Containers die daarna nog draaien krijgen een SIGKILL signaal, wat ze geforceerd stopt.
- De Pod wordt verwijderd.
Gebruik Readiness and Liveness Probes
Readiness and liveness probes kunnen beide gebruikt worden om aan te geven dat een Pod beschikbaar is voor verkeer. Tot deze functies Ready aangeven zal deze nog geen verkeer verwerken. Bekijk de Configure Liveness, Readiness and Startup Probes documentatie van Kubernetes hoe je dit kunt implementeren.
Gebruik Resource Management
Om te zorgen dat je applicatie altijd gescheduled kan worden, kun je limieten instellen voor de pods. Bekijk Resource Management for Pods and Containers om te zien hoe je dit kunt gebruiken. Indien je te krappe limieten stelt voor je applicatie kun je bijvoorbeeld Out-Of-Memory foutmeldingen krijgen, dus let wel goed op.
Gebruik een PodDisruptionBudget
Een PodDisruptionBudget defineert hoeveel instances van een service kunnen missen zonder dat deze down gaat. Bekijk de Specifying a Disruption Budget for your Application pagina uit de Kubernetes pagina om duidelijk te krijgen hoe dit precies in zijn werk gaat.
Affinity and anti-affinity
Spreid Pods die een High Available dienst leveren over verschillende nodes met anti-affinity. Dit zorgt ervoor dat de kans kleiner is dat er meerdere Pods van een dergelijke dienst tegelijk van één node gemigreerd hoeven worden en maakt het proces betrouwbaarder in combinatie met het PodDisruptionBudget. Kijk op de Assigning Pods to Nodes pagina uit de Kubernetes documentatie voor meer informatie.
Container Registries & Rate Limits
Registries kunnen een rate limit hanteren (zoals Docker Hub), omdat alle nodes worden vervangen worden alle containers opnieuw gedownload. Hierdoor kun je ImagePullBackOff errors krijgen en komt je applicatie misschien erg traag weer online. Afhankelijk van de siutatie zijn er de volgende alternatieven (te combineren); inloggen (eventueel met een subscription), alternatieve registry's, een eigen registry of pull through cache opzetten.
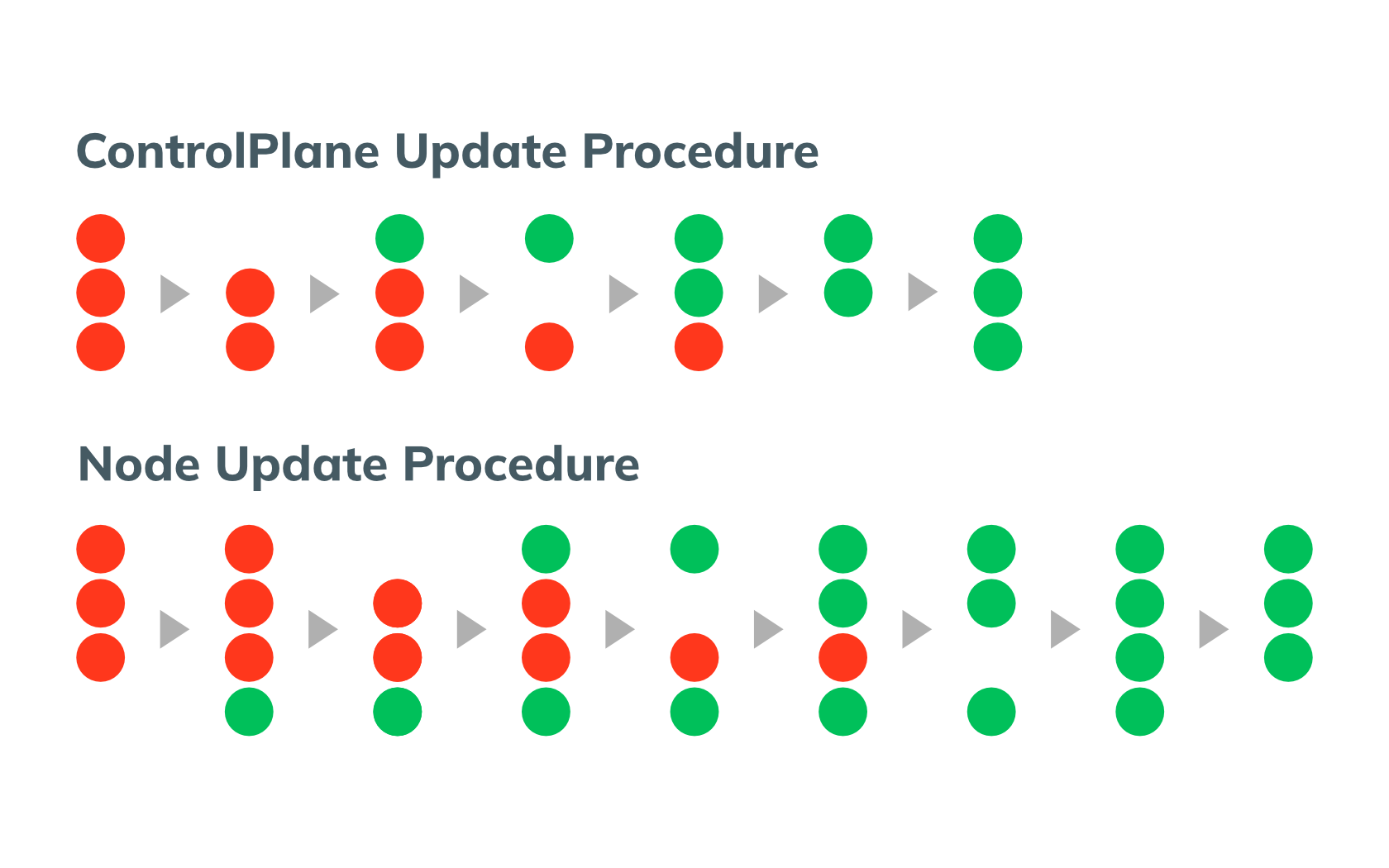
Het updateproces
Als je applicatie de best practices volgt, kan het cluster worden geupgrade zonder downtime.
Eerst worden de control planes één voor één geupdate en wordt een tijdelijke extra workernode aangemaakt. Hierbij zullen Kubernetes API request en kubectl-commando's tijdelijk niet beschikbaar zijn. De diensten op de workernodes zullen hier geen impact van ondervinden. Daarna worden alle workernodes één voor één gedrained en vervangen voor geupgrade workernodes. Uiteindelijk wordt de tijdelijke workernode gedraind en uit het cluster verwijderd en is de update voltooid.
Tijdens de update worden alle nodes (en control planes) vervangen door nieuwe instances. Wees er daarom zeker van dat alle data die behouden moet blijven op Persistent Volumes staat!